How Kemon Runs AI Agents on Live Production Servers
How Kemon Runs AI Agents on Live Production Servers
Keywords: claude code production server, ai agent devops, mcp server automation, ai-driven ops agency
Introduction
Most AI implementations treat agents as chat tools or code generators. At Kemon, we operate AI agents as production infrastructure operators. They run directly on live servers, manage deployments, fix infrastructure, and execute diagnostics that would otherwise require days of developer time. This article explains how we've built the safety protocols, operational patterns, and tooling to make it work at scale.
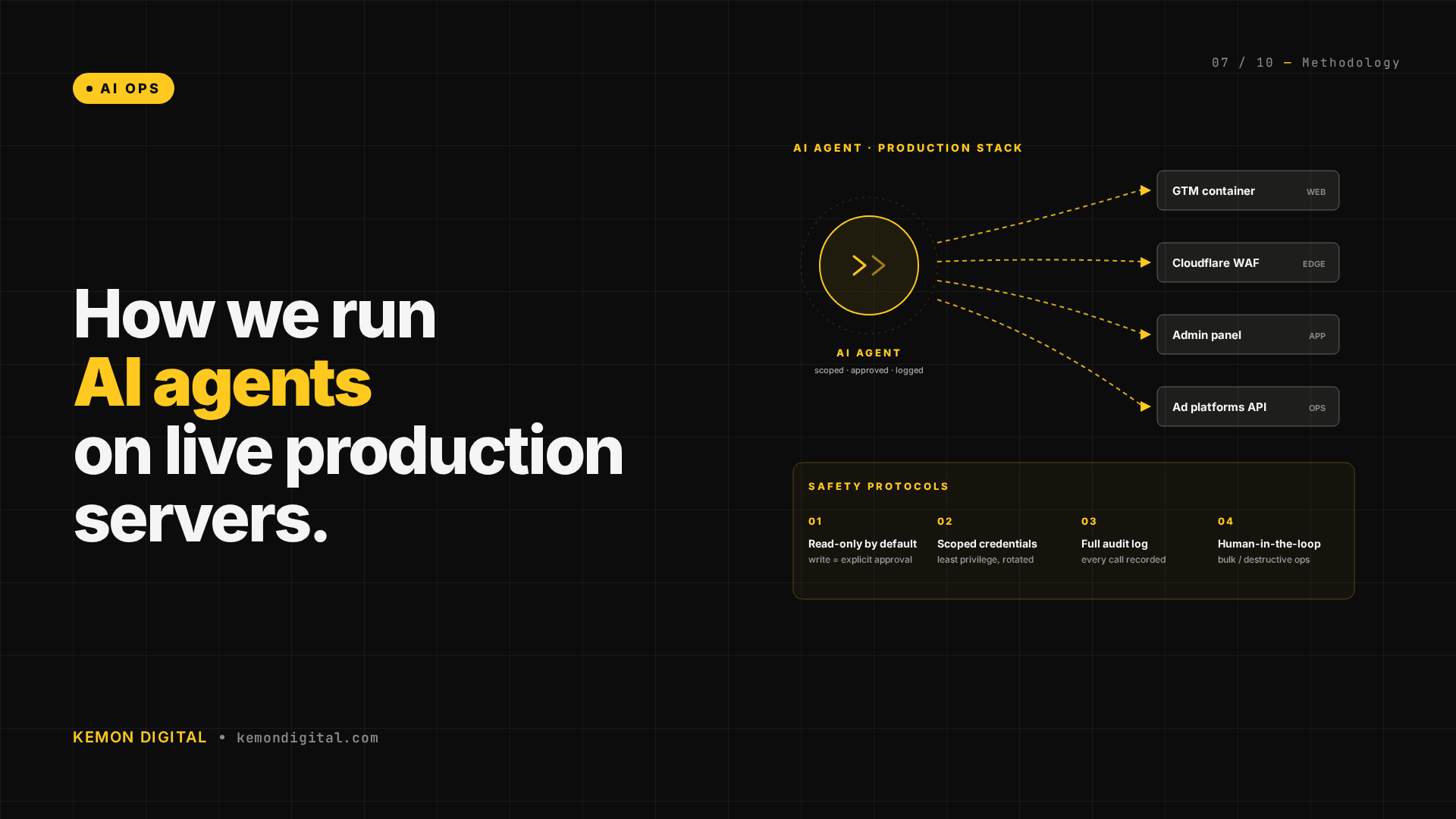
What It Means to Run AI Agents on Production
Running an AI agent on live infrastructure is fundamentally different from using AI to draft code or generate content. You're asking the agent to:
- SSH into production servers and edit configuration files
- Deploy code and restart services
- Analyze multi-million-line production logs
- Make decisions about infrastructure that affect customers directly
This requires accountability. Our agents operate under the Live Site Protocol — a set of risk assessments, backup procedures, approval gates, and rollback patterns that ensure no production change is irreversible.
The Infrastructure Stack
We manage three classes of production infrastructure:
Client E-Commerce Platform (DigitalOcean)
- Rails backend with Passenger application server
- Nginx reverse proxy with cookie-gated routing
- PostgreSQL database with Redis caching
- SSH access to manage deployments, logs, and infrastructure
Kemon Infrastructure (Hostinger VPS)
- Next.js frontend with PM2 process management
- Email infrastructure (Dovecot IMAP, Postfix SMTP)
- Systemd services and health checks
- SSL certificate management via certbot
Cloud Services (Browser Automation)
- Cloudflare WAF rules and DDoS protection
- Google Ads campaigns and bid strategy management
- Google Analytics 4 measurement stack validation
- Notion workspace and documentation management
Real Production Actions We've Shipped
Routing and Load Management
- Implemented cookie-gated routing for Next.js product page A/B testing
- Right-sized Passenger worker pools based on request queue analysis
- Created Cloudflare WAF rules to block malicious traffic
- Deployed autossh tunnels for infrastructure connectivity
Code Deployment
- Deployed GTM measurement changes via SSH-editing Rails templates
- Generated and deployed SSL certificates with DNS validation
- Created DNS records (A, CNAME, MX) via hosting provider APIs
- Deployed Next.js updates with zero-downtime restarts
Infrastructure Maintenance
- Fixed Dovecot email authentication errors
- Added systemd health-check cron jobs
- Analyzed production logs to identify error patterns
- Ran Rails database queries and migrations
Operations and Diagnostics
- Extracted and analyzed production logs
- Debugged session and cookie issues
- Validated GA4 measurement stack integrity
- Backtested TradingView trading indicators
The MCP Stack: Extending Agent Capabilities
Model Context Protocol (MCP) is how we extend AI agent capabilities beyond SSH and basic CLI tools:
- TradingView MCP — Chart control, indicator management, backtesting, data extraction
- Alpaca MCP — Trading API integration, market data, account management
- Gmail MCP — Email management for alerts and handoffs
- Notion MCP — Workspace and database management
- Chrome MCP — DOM-aware browser automation for cloud services
This lets agents operate across infrastructure silos in a single coherent loop without custom integration code.
Safety Protocols: How We Prevent Catastrophes
The Live Site Protocol has three phases:
Before Production Changes
- Risk classification (kill-switch reversibility, blast radius)
- Config backups and database snapshots
- Approval gates for medium/high-risk changes
During Execution
- Full logging and audit trails
- Kill-switch patterns (revert in 30 seconds)
- No cascading failures
After Deployment
- 5–10 minute monitoring period
- Error rate and health check validation
- Immediate rollback if anomalies emerge
The Competitive Advantage
What used to take a developer 3–5 days now takes 30 minutes. Infrastructure audits that required manual investigation now run autonomously. Code deployments that required coordinating multiple stakeholders now execute with a single approval gate.
The safety protocols aren't overhead — they're what make this possible at scale. Every guardrail (backups, logging, approval gates) eliminates risk and enables speed.
Why This Matters for Your Business
If your infrastructure operations are bottlenecked by:
- Manual deployment steps
- Context-switching between tools
- Firefighting instead of proactive operations
- Audit trails that don't exist
AI-driven operations can solve these problems — but only with proper guardrails in place.
FAQ
Q: Isn't it risky to run AI agents on production servers?
A: Yes, if you don't have guardrails. Our Live Site Protocol makes it safe: risk assessments before changes, backups before edits, approval gates for medium/high-risk changes, and kill-switch patterns that let us revert in 30 seconds. We've caught more problems in the backup and approval phases than we've ever had to roll back.
Q: What happens if the agent makes a mistake?
A: We catch it in two places: the approval phase (for medium/high-risk changes) and the monitoring phase (5–10 minutes post-deployment, watching error rates and health checks). If an issue emerges, we roll back immediately. We never push through anomalies hoping they resolve.
Q: How long does it take to set this up?
A: The infrastructure is custom to our stack. But the pattern is portable: you need SSH access, logging, backups, approval gates, and kill-switch patterns. The MCP stack (TradingView, Alpaca, Gmail, Notion, Chrome) plugs in via API, not custom code.
Q: Can you do this on Kubernetes / serverless / my cloud provider?
A: Yes. The pattern is: SSH access (or equivalent), infrastructure as code (Terraform, CloudFormation), version control, and approval gates. Kubernetes deployments follow the same protocol as Rails deployments. Serverless functions can be managed via API (Lambda, Cloud Functions).
Q: What about compliance and audit trails?
A: Every SSH command is logged. Every config change is version-controlled. Every deployment is timestamped and annotated. This creates a complete audit trail for compliance, debugging, and post-mortem analysis. We store logs for 90 days minimum.
Q: How much does AI-driven operations cost?
A: Less than hiring a DevOps engineer, and faster than the context-switching cost of ad-hoc operations. An agent can run 24/7 health checks and diagnostics without human intervention. Deployments that take a day of developer time take 30 minutes.